ML Engineer - 5 Years of Experience - Reflection
A deep dive into my career progression over the last 5 years at Visional Inc - From junior ML engineer to technical lead
Five years ago, I embarked on my journey at Visional Inc., as a fresh graduate eager to contribute to the AI and Machine Learning landscape in Tokyo, Japan. Three years ago, I penned my 2-Year milestone recap that I had documented earlier and I believe that I have grown exponentially since then.
Now, as I stand at the cusp of my fifth anniversary, it’s a good time to reflect on the evolution of my role, my achievements, and the exciting challenges that have shaped me into the engineer I am today.
Contents
Revisiting My Foundations
When I was writing my 2-Year recap blog, I was still finding my footing in the world of Machine Learning, juggling between different roles as a Data Scientist, ML Engineer, and Research Scientist. I was focused on delivering value through the projects I worked on, projects that were critical in building my technical foundation, allowing me to dive deep into the practical aspects of ML workflows.
As I transitioned into the next phase of my career, I began to realize the importance of not just being an effective contributor but also taking on leadership roles within projects, especially in shaping their direction and execution. This leads to what I believe were key developments in the last three years.
1. A New Manager: Better communication
One of the most significant changes in my professional life was my Vietnamese team lead becoming my manager. This transition had a profound impact on how I approached my work. Being able to directly converse in English with my manager, not only about technical issues but also management-related concerns made me more comfortable in my place within the team.
I found myself more involved in the early roadmapping phases of projects. A notable example was the Resume Generation project, a super impactful project where I was able to contribute right from the brainstorming stage. This involvement gave me the confidence to push for innovative solutions to both technical and management related issues. I am truly grateful for having him as my manager.
2. OKRs: Linking Personal and Professional Growth
Another shift in my professional growth came from my adoption of personal OKRs (Objectives and Key Results), a practice inspired by Google’s approach, which I learned from reading the book Measure What Matters by John Doerr.
I had initially struggled with the company’s MBO (Management by Objectives) system, not knowing how they would link back to the broader company objectives OR my own career goals. OKRs are designed to be transparent and cascaded through organization levels.
Adopting such a practice for my personal goals taught me how I could link my work with my career goals, focusing on outcomes rather than output. This personal system kept me on track, ensuring that my work was always purposeful and aligned with both my professional growth and the company’s vision.
3. Continuous "Deep" Learning
Reading Designing Machine Learning Systems by Chip Huyen was a game-changer for me. The book provided me with a comprehensive understanding of ML systems, evolving my notion of machine learning beyond just developing an End-to-End Pipeline, to a holistic Machine Learning Life Cycle. Learning best practices in designing scalable and reliable ML systems is crucial for moving from experiments/internal projects to production-grade applications.
The book particularly emphasized the significance of MLOps - a trend that was coincidentally gaining momentum within our team, thanks in part to a new colleague who had joined us from AWS as an MLOps Architect. Our discussions went beyond the basics of MLOps; I gained insights into concepts like Teal Organizations, Team Topologies and various frameworks for logical thinking. Aimed at this new direction, we proposed a re-architecture of our AI MLOps, focusing on scaling our infrastructure and improving the reliability of our models in production. This initiative was a key milestone in my journey, marking the transition from contributor to thought leader within my team.
4. Tools for Enhanced Productivity
When a person with ADHD who has always been an academic achiever finds themselves unable to change jobs, be it due to fear of change, high standards or even emotional attachment, they begin to devise personalized workflows to keep up with increasing complexity at work.
Google Meets’ closed captioning and the Google Translate browser extension allowed me to better understand meetings, ensuring that I remained an active participant regardless of language barriers. The move from Confluence to Scrapbox as a documentation tool in our company, which is coupled with DeepL for translations, also helped me bridge the language gap.
Outside the language barrier, Miro became indispensable for system architecture designs and big-picture mind maps, helping me and my team visualize and communicate complex ideas effortlessly. Tools like ChatGPT/Copilot for code improvement, debugging, and documentation significantly boosted my productivity.
My Projects
The past three years have been transformative, owing to key projects which not only tested my technical skills but also pushed me to grow as a leader and innovator in the ML space. I found myself going the extra mile, partly due to the demands of the project and partly due to the passion and satisfaction I discovered while working on them.
1. Resume Generation (Multiple Versions)
The Resume Generation project has been an ongoing effort, with several key milestones achieved over the last three years - even prior to the advent of ChatGPT. The project evolved through multiple versions: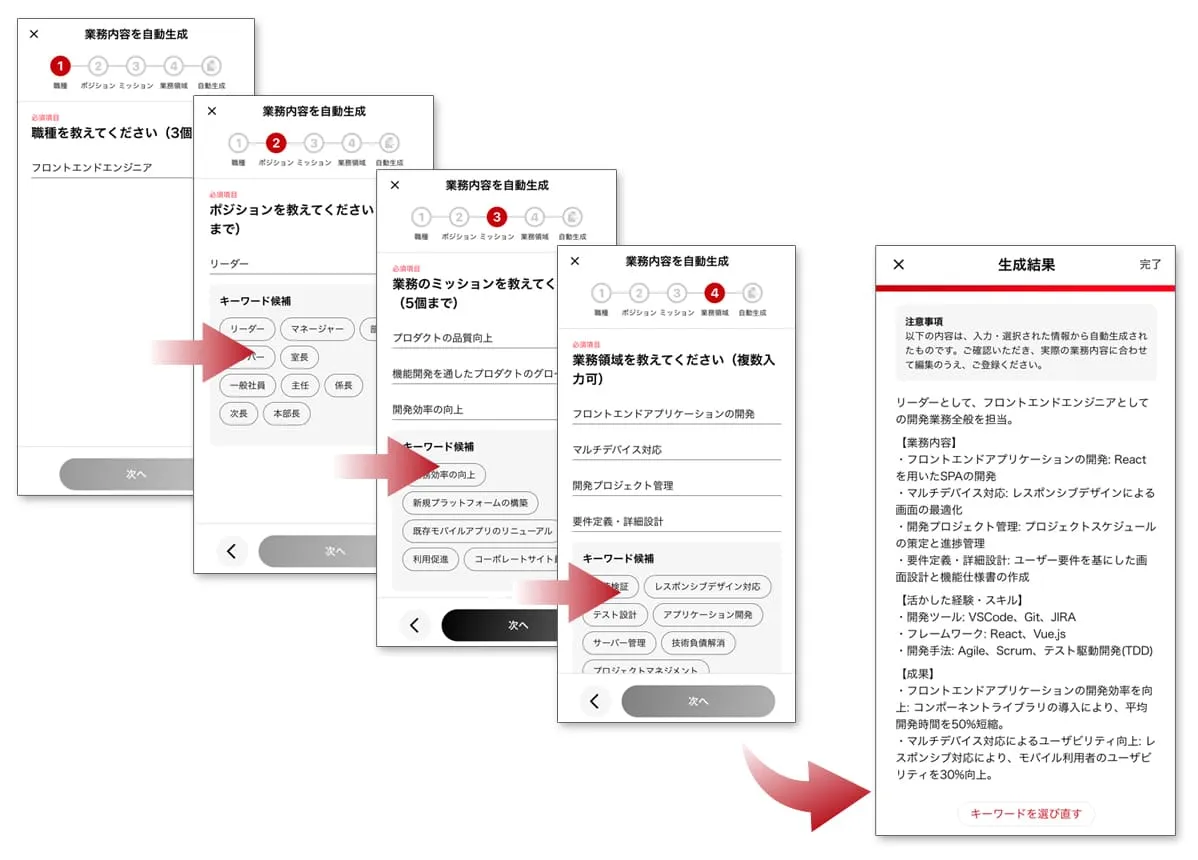
V1: Keyword Suggestion
The first form of AI assistance our platform could provide candidates in the registration process was suggesting them relevant keywords to enhance their profiles. This version leveraged tfidf and k-means clustering to recommend relevant keywords, helping candidates improve their profiles and increase recruiter visibility and scout rate. I joined as this version went live.
V2: Keyword — Sentence Recommendation
We took things further with a two-step pipeline:
-
Keyword Recommendation
Resume features (text/categorical) were vectorized and concatenated to form a resume vector. Topic modeling using LDA was used to create an embedding model for resume-keyword similarity.
-
Sentence Recommendation
A BERT Semantic Textual Similarity (STS) model was trained to recommend sentences similar to keywords selected in the previous step.
V3: Keyword — Text Generation
With the release of ChatGPT, we rapidly prototyped with OpenAI’s API and moved to a microservices architecture. This phase saw a lot of cross-team collaboration and high-tempo releases.
Following the success of V2, we went with a two-step pipeline:
-
Keyword Recommendation Improvements
The embedding model for resume-keyword similarity was iteratively improved in order to improve candidate-recruiter matching metrics. Using user feedback features such as candidate keyword selection rate and recruiter search keyword popularity for reranking was found to be the most effective.
-
Text Generation System Design
A microservices-based architecture was designed to efficiently handle the resume generation request loads:
- Implemented message-forwarding and queuing via AWS SQS and DynamoDB
- Multithreading capabilities, processing up to 60 Generation RPM, within OpenAI’s rate limits
- Internal error mapping to manage OpenAI’s success/error responses
- Moderation layers to act as guardrails to reinforce the
harmlessin the 3Hs for LLMs
The system required high cross-team collaboration with product backend, frontend and QA teams. I took the initiative to create the first Datadog dashboard for the AI team, making it easy to share weekly insights, respond to incidents, improving the flow of communication on the AI side.
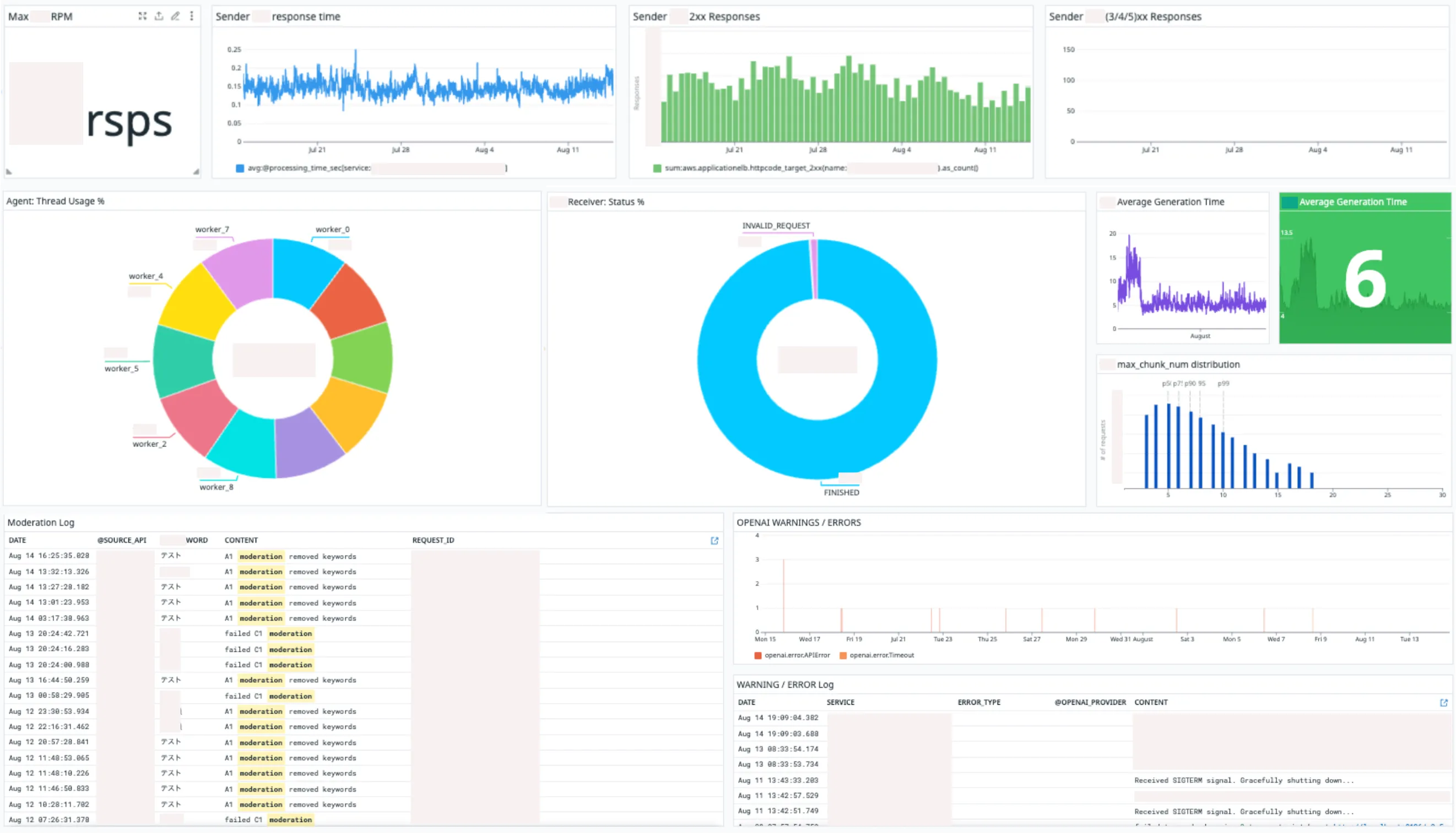
The impact? A 40% improvement in our scout-reception KPIs!
Oh, and the team received the Best Project Team Award at the BizReach Awards 2023. Look at the size of the team! The memories of that project are still fresh, and the award ceremony—a reminder of how collective effort and innovation can lead to extraordinary results.

Almost a year has passed since then, and with the system architecture in place, the focus shifted to optimizing performance:
- Optimized recommendation using BERT embeddings to better capture keyword-resume similarities
- Improved prompts across different job categories, guided by prompt engineering best practices
- Improved incident response, reducing time-to-detect (TTD) and time-to-mitigate (TTM) by adding more alerts and implementing redundancy measures, such as provider/region switching
- Supporting multi-API integration, ensuring backward compatibility while introducing new features
ChatGPT was released to the world in the beginning of Dec 2022. Within days, our senior
engineers had built a prototype with the text-davinci-003 API, which led to rapid
developments post-New year. A large project team was formed, including frontend,
backend, ML, QA, legal, etc., and I found myself sitting beside my manager on the
largest Japanese round table in my life, and between listening hard to navigate
fast-paced discussions and vaguely looking at my manager, I was trying to fit
together context like pieces of a jigsaw. I made through it - somehow, and was set
to release the first version of the new ML system within 2 months, the backbone
to what became one of the most intense, yet rewarding, phases of my career so far.
Those two months of development felt like a throwback to my university days,
filled with late hours and deep focus. But that’s a story for another time!
The Resume Generation project has been one of the most impactful projects I’ve worked on, significantly contributing to the company’s core offerings and demonstrating my ability to lead and deliver in complex, multi-phase projects.
2. AI MLOps: Feature Store PoC
Inspired by reading Designing Machine Learning Systems by Chip Huyen and learning about best practices in a holistic Machine Learning Life Cycle, I got deeply involved with our MLOps team in leveling up our MLOps game. Together, we identified a technical debt in the form of overlapping feature engineering work across ~30 batch pipelines in production.
I remember the frustration I felt building a search feature pipeline from scratch in my first year, only to realize later that a similar one already existed in another team’s repo. I have always had a passion for automation and standardization. I highlighted the need to centralize features across multiple pipelines and proposed the re-architecture of our AI MLOps systems, centered around developing AI Group’s first Feature Store PoC, a single source of truth for engineered features.
Although it is still early in my MLOps journey, I’ve found Google’s documentation invaluable, especially their a Golden Path to MLOps, which became my blueprint for understanding how to incrementally build an organization’s MLOps capabilities across CI/CD/CT pipelines. It shows how higher levels of automation could accelerate the ML lifecycle. Higher the level, higher the velocity of deploying new models given new data/implementations.
Of course, every organization’s MLOps journey is unique. Following the Vertical First Horizontal Second, approach, we prioritized rapid vertical prototypes to detect risks early and iterate quickly. Over time, expanding horizontally becomes essential to increase team breadth and coverage.
While our journey towards MLOps maturity shares commonalities with Google’s levels, it is not a direct testament to Google’s MLOps level definitions. Instead, it reflects our unique path, tailored to our specific challenges, infrastructure, and business needs. Understanding our starting point and mapping our progress has helped us focus on meaningful improvements:
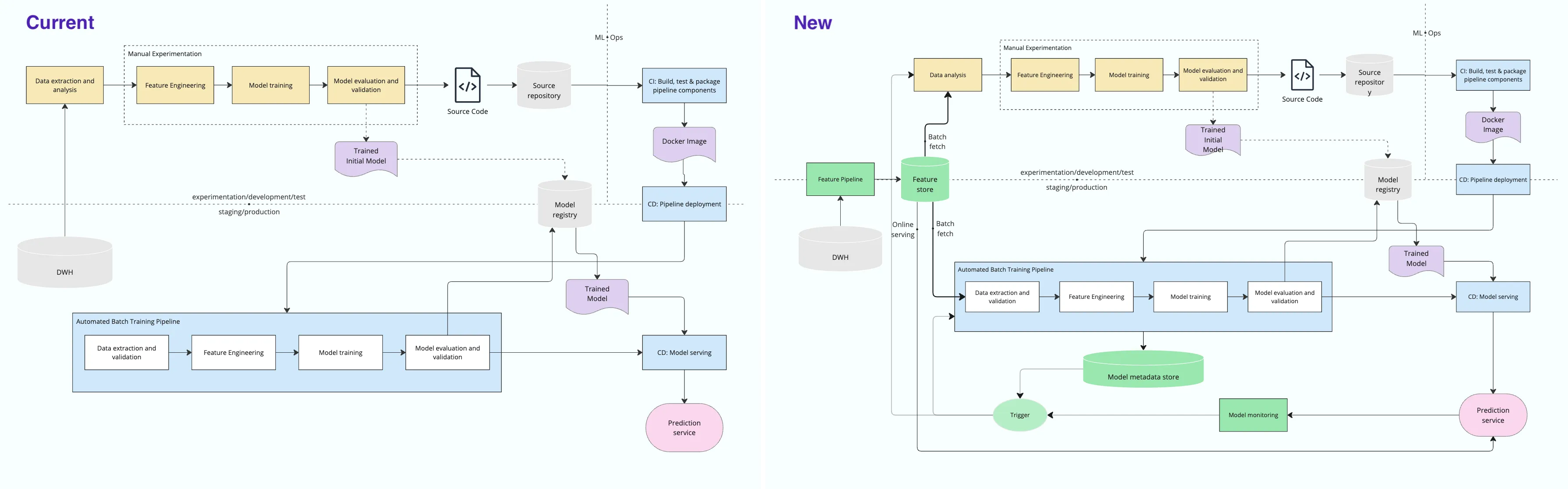
Once our MLOps vision reached a practical stage, we attended a 2-day Google MLOps Mini TAP (Tech Acceleration Program) at the Google Tokyo Office to refine our MLOps direction using Google Cloud’s solutions. We decided to implement the first PoC using Vertex AI.
For the PoC, I led the design and implementation of the feature store schema, decoupling data and model pipelines for a low-impact score prediction project - a perfect case for standardization due to its feature overlap with others. It was a hands-on process, requiring a lot of self-study, but it gave me a deep understanding of the core components:
- Data Pipeline: Apache Beam, Google Dataflow (flex-templates)
- Model Monitoring: Vertex AI Model Monitoring
- Online Feature Serving: Vertex AI Feature Store
Meanwhile, my colleague focussed on model training, evaluation and registration. We later integrated everything into a coherent workflow using Kubeflow Pipelines (kfp).
Looking back, this PoC was a major step forward for us. It wasn’t just about implementing new technology but the groundwork for scalable, efficient ML at our company. There’s a lot to do next term!
3. Resume LLM Fine-tuning (R&D Project)
In an effort to stay at the cutting edge of the recent boom in AI and LLMs, I took on the challenge for an R&D project focused on fine-tuning a Large Language Model (LLM) for resume generation, building upon my work on the Resume Generation project.
This project was particularly challenging as it involved working with vast amounts of unstructured text data and adapting a pre-trained LLM to our specific domain. The main aim was to explore the feasibility of developing an in-house LLM to reduce the dependence on external models like ChatGPT. A secondary outcome was to establish a baseline PoC for LLM fine-tuning within our AI Group.

With the LLM boom in full swing, I jumped into an R&D effort to fine-tune large language models for resume generation—hoping to see if we could eventually reduce our reliance on external models like ChatGPT. As the sole contributor, I wore many hats:
- Self-learning and Methodology review
- In-depth review of LLM fine-tuning methods such as LoRA and PEFT
- Surveyed various pre-trained and fine-tuned models in the HuggingFace documentation
- Completed the Generative AI with Large Language Models course offered by DeepLearning.AI and Amazon Web Services to enhance my understanding of these techniques
- Data Engineering and training data curation
- Data sampling ensuring high alignment with business KPIs along with diversity and representativeness
- Extracting features from candidate resumes using NLP techniques
- Structured these features into prompts with the
Alpaca formatfor instruction fine-tuning (supervised)
- Base model selection: elyza/ELYZA-Japanese-Llama-2-7b-fast-instruct
- open-source 7B parameter model with Japanese language capabilities
- fine-tuned on Meta’s Llama2 Large Language Model
- Fine-tuning Experiments
- QLoRA (using bitsandbytes and PEFT) to optimize compute budget
- Tuning batch sizes to optimize memory and training time
- Filtering prompt lengths to reduce memory usage (irregular padding) and increase batch sizes
- LLMOps
- Running large parametric TrainingJobs from small SageMaker notebook instances
- Logging results and metrics (eg. ROUGE score) to S3 for quality feedback from domain experts, crucial in refining the model and improving output quality
In the end, as expected, there was much room for improvement. It requires a lot more effort to achieve expected metrics and quality to beat a proprietary external LLM. Enhancing data size and quality, tuning model parameters, implementing iterative evaluation with human feedback (RLHF) were some of the ways in which I could have refined performance. While we didn’t fully surpass external models, we established a working baseline and a roadmap for future LLM projects within our AI group.
4. Financial Document OCR System Improvements
Building on the success of the initial Financial Document OCR system, I led 2 major improvement phases that further enhanced the system’s accuracy and usability.
-
The first phase focused on improving the text recognition accuracy, particularly for documents with poor scan quality or complex layouts. I incorporated advanced image preprocessing techniques such as noise reduction, skew correction, and adaptive thresholding. The qualitative evaluation score passed for 90% of the test files as a result, increasing from around 85% last term. As an extra, the output format was changed from XLS to XLSX for better compatibility.
-
The second phase aimed at expanding the support for 4 new types of documents. I designed image processing algorithms able to deal with tables with defined cell boundaries as well as processing wrapped text in such cells. The format detection logic was updated to support both old and new algorithms.
While I am aware that new and faster methods using multi-modal LLMs are now available, but at that time, these improvements had not only enhanced the system’s performance but also reduced the manual effort required in processing financial documents, leading to substantial time savings and increased productivity for the team. A benchmarking by the Succeed team proved the internal tool to be better than Line Works OCR tool in terms of data privacy, ease of use and specialized usecase.

About Visional

Established in April 2009, BizReach has been operating a variety of Internet services that support the future of work in Japan with a mission that roughly translates into “creating a society where everyone can believe in their own potential”. The company, headquartered in (Shibuya) Tokyo, has regional offices in Osaka, Nagoya, Fukuoka, Shizuoka, and Hiroshima.
Visional was born in February 2020, when Bizreach Inc. shifted to a group management structure. The company has continued its significant role in Japan’s HR Tech and SaaS sectors that promote digital transformation (DX) of industry and support the improvement of productivity in Japan.
Within the last 3 years, Visional Inc. was also listed on the Tokyo Stock Exchange.
- Initially listed on the TSE’s Mothers segment on April 22, 2021, Visional successfully
- transitioned from the Growth Market segment to the Prime Market segment on December 14, 2023.
- The company has demonstrated strong financial performance. As of late July 2024, Visional
- was trading at a price around 9,370 JPY with a market cap of approximately 367.44 billion JPY.
- Their P/E ratio stands around 24.66 and a significant profit growth of 53.2% YoY in FY2024 Q3.
Visional has strengthened its HR Tech segment, and platforms like BizReach and HRMOS are central to helping companies utilize human resources based on data-driven insights. The incubation segment has also seen significant growth, focusing on developing new businesses in areas with high market potential, particularly in logistics and B2B services.
The group broadly has a heirarchical structure with the following products and services:
- Visional Corporation, the holding company, supports the group management
- Bizreach Corporation, responsible for the management of the original HR Tech and SaaS businesses
- Bizreach, a professional HR platform that connects companies with available talent
- HRMOS Talent Management, an employee management platform
- HRMOS Recruitment, an recruitment management system
- HRMOS Attendance, an attendance management system
- HRMOS Expenses, an expense settlement system
- HRMOS Payroll, a payroll management system
- Bizreach Campus, an alumni network service for career consultation
- Visional Incubation Corporation, responsible for new business development and acquisitions
- M&A Succeed, an M&A platform for business succession
- Yamory, security vulnerability management cloud for IT systems
- Trabox, a platform focused on digital transformation in the logistics industry
- Assured, a cloud security risk assessment service
- StanBy, a job-search engine jointly owned with Yahoo Japan
Each of the products have their own specific engineering teams that follow custom Agile software development life cycles (SDLCs) they are comfortable with.
The AI Team is a team of around 20 ML/AI engineers that collaborate with one or more of the above mentioned products to understand their business requirements, and leverage data to deploy AI features in production environments to drive business solutions.
The Road Ahead
The last three years have not just been about professional growth; they have also been about personal development. Adopting OKRs, improving my communication skills in a multilingual environment, and taking ownership of more complex projects have all contributed to a more holistic growth trajectory. I’ve learned to balance my technical expertise with strategic thinking, ensuring that I can contribute effectively both as an engineer and as a leader.
As I look forward to the next phase of my career, I am excited about the possibilities that lie ahead. After a quarter of my life, I am well aware that I shall always be a Jack-of-all-Trades. Whether it’s further deepening my expertise in MLOps, taking on more leadership roles, or exploring new domains within LLM applications, I am confident that the foundation I’ve built over these five years will serve me well.
Also, after all these years, I am happy that I can say 頑張りましたね!, instead of my usual eigo tabemasen.. lol.
This blog serves as a continuation of my reflection from three years ago. If you’re interested in understanding how it all began, feel free to check out A Look Back at My First Full-Time Job.